

- 人間が普段話したり書いたりする言葉をコンピュータに理解・処理させる技術のこと!
- それが膨大なテキスト情報の分類や翻訳を自動化し、対話型AIによる正確な受け答えを支える役割を果たします。
- 現場で使うとアンケート分析や顧客対応の自動化など、人間が行っていた情報の読み解き時間を劇的に短縮できるという良い変化があります。
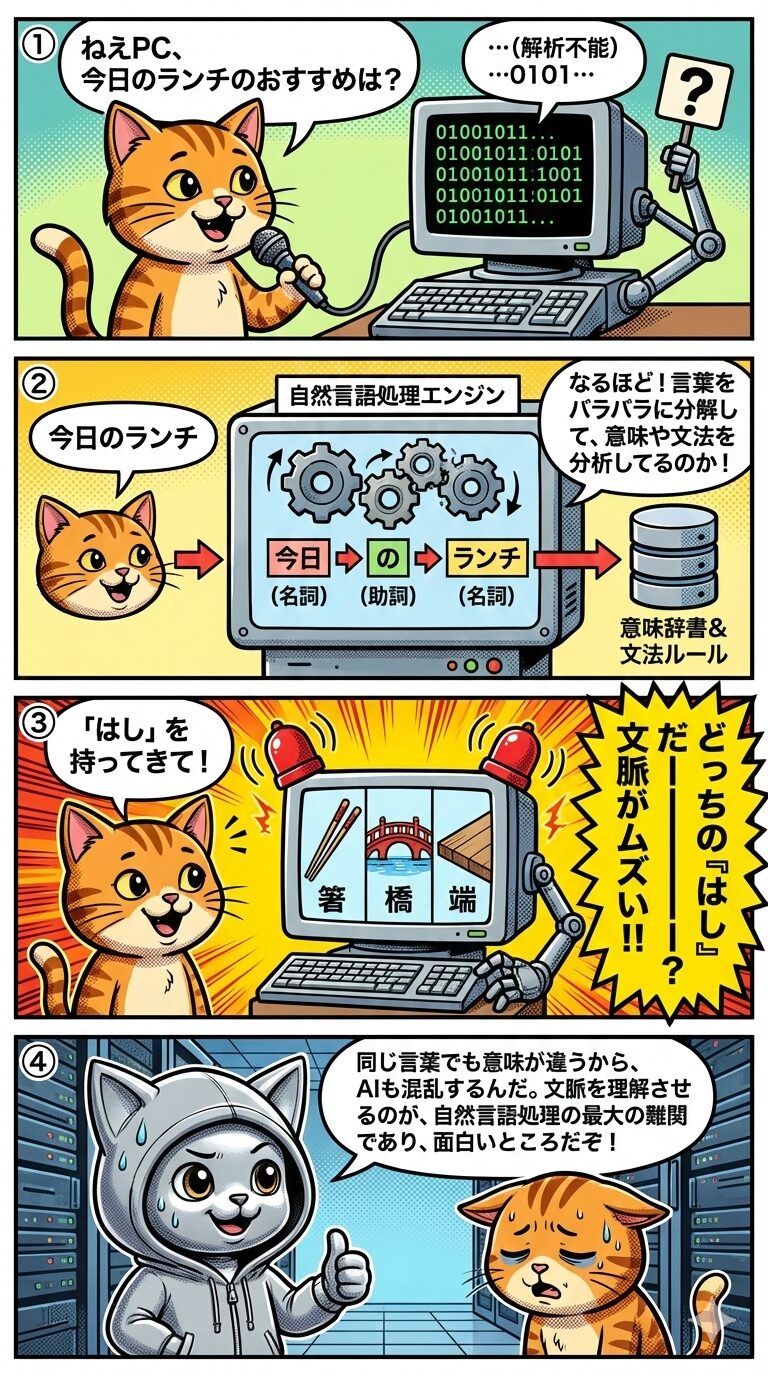
自然言語処理は、私たちが日常的に使う言葉をコンピュータに理解させるための重要な技術です。漫画の第2コマで描かれているように、文章を単語単位に分解して品詞を特定する形態素解析などは、その基礎的なプロセスとなります。しかし、実務における最大の壁は、第3コマにあるような言葉の「曖昧性」です。
「はし」というたった一つの言葉でも、文脈によって「箸」「橋」「端」と意味が全く異なります。このような同音異義語や多義語の存在は、企業のカスタマーサポート用チャットボットなどが顧客の意図を誤解し、不適切な回答をしてしまう誤応答リスクに直結します。これは顧客満足度の低下を招く経営的な課題となりえます。
したがって、実用的な自然言語処理システムの構築には、単語の意味だけでなく、前後の文脈から最適な意味を推測する文脈理解の精度向上が不可欠です。AIが人間の意図を正確に汲み取れるようになることこそが、この分野における最大の挑戦であり、ビジネス価値を生む源泉となるのです。
【深掘り】これだけ知ってればOK!
自然言語処理は、英語でNLP(Natural Language Processing)と呼ばれます。コンピュータは本来、数字しか扱えませんが、この技術を使うことで言葉をバラバラに分解し、単語同士の関連性を分析できるようになります。具体的には、文章を最小単位に分ける形態素解析や、文の構造を調べる構文解析といった手順を経て、最終的に機械が意味を抽出します。
会話での使われ方
今回のカスタマーサポートの自動化には、最新の自然言語処理ライブラリを活用しましょう。
開発プロジェクトのキックオフで、具体的にどのような技術を用いて課題を解決するかを提案している場面です。
SNSの投稿データを感情分析にかけて、新製品の反響を数値化してください。
マーケティング担当者が、テキスト情報から顧客の満足度を客観的なデータとして抽出するよう指示しています。
君が作った形態素解析の辞書のおかげで、業界用語の判定精度が上がったよ!
専門用語が多い現場で、後輩が独自にシステムをカスタマイズした成果を先輩が認めています。
【まとめ】3つのポイント
- 言葉のデジタル翻訳機:曖昧な人間の言葉を、コンピュータが処理できる整然としたデータに変換します。
- 膨大な情報の整理整頓:人間では一生かかっても読み切れない量の文書から、必要な情報だけを瞬時に見つけ出します。
- 円滑な意思疎通の土台:翻訳や要約、音声アシスタントなど、人と機械のコミュニケーションをより自然なものに変えます。
よくある質問
- Q自然言語処理はいつ使うのがベストですか?
- A大量のテキストデータから傾向を掴みたい時や、多言語対応のサービスを構築したい時、またはチャットボットで自動応答を作りたい時です。
- Q自然言語処理を失敗させないコツはありますか?
- A分析対象のドメイン(専門領域)に合わせた辞書やモデルの選定をすることです。一般的な言葉と専門用語では意味が異なる場合があるためです。
- Q自然言語処理の具体例は何ですか?
- AGoogle検索の予測変換、DeepLなどの機械翻訳、迷惑メールの自動フィルタリングなどが身近な例です。
- Q自然言語処理とLLM(大規模言語モデル)との違いは何ですか?
- A自然言語処理は技術全体の名前です。LLMはその中の一種で、特に巨大なデータで学習させた、より高度な推論ができるモデルを指します。

コメント